Sur les écrans d’accueil, Discover n’a plus rien d’un simple flux “sympa à consulter” entre deux rendez-vous. Pour beaucoup d’éditeurs, c’est une rampe d’accès directe à des lecteurs qui ne tapent plus forcément de requêtes, mais qui consomment l’actualité au fil des cartes. Or, depuis quelques mois, un signal devient impossible à ignorer : Google resserre les boulons. L’objectif est clair, même s’il se décline en multiples micro-décisions de tri : réduire la visibilité des contenus synthétiques publiés en volume, surtout lorsqu’ils sont non sourcés, peu attribués, ou éditorialement “flous”. Ce n’est pas une croisade contre l’IA en tant qu’outil, mais un ajustement vers une logique de confiance : qui parle, au nom de qui, avec quelles sources, et selon quel niveau de qualité de l’information ?
Dans un écosystème où des sites opportunistes ont appris à produire des centaines d’articles par jour, parfois avec des signatures fictives, l’enjeu dépasse la technique. Il touche à la crédibilité des médias, au modèle économique de la recommandation, et à la sécurité informationnelle. Pour illustrer ce basculement, suivons le cas d’“HexaMedia”, une rédaction numérique française fictive : son trafic Discover a longtemps compensé la baisse de la recherche. Puis, après une série de changements et quelques alertes en Search Console, son audience s’est mise à osciller. La leçon est brutale mais utile : sur Discover, l’époque où “publier beaucoup” suffisait s’achève. Place à la preuve, à la transparence et à la cohérence éditoriale.
Google Discover revoit son algorithme : limiter la visibilité des contenus synthétiques non sourcés
Le cœur du mouvement tient en une phrase : l’algorithme de Google qui orchestre Discover valorise davantage les signaux de fiabilité et pénalise ce qui ressemble à une production industrielle. Cela ne signifie pas que tout texte assisté par IA est rejeté. En revanche, les contenus synthétiques “sans chair”, sans contexte, sans auteur clair, et surtout sans sources identifiables, deviennent des candidats naturels à la limitation de diffusion.
Dans la pratique, les équipes SEO observent un phénomène connu dans d’autres surfaces Google : au lieu d’une unique “grosse” mise à jour, on voit des ajustements continus. Pour HexaMedia, cela s’est traduit par des journées très fortes, suivies d’une retombée soudaine sur des clusters d’articles “rapides” (brèves tech et actu divertissement). Les dossiers plus travaillés, eux, ont mieux résisté. Pourquoi ? Parce que Discover fonctionne comme une vitrine : il doit protéger l’utilisateur contre le sentiment d’être manipulé ou mal informé.
Le rôle des sources et de l’attribution dans la qualité de l’information
La qualité de l’information sur Discover ne se réduit pas à l’orthographe ou au style. Elle se lit à travers des indices vérifiables. Une actualité économique sans lien vers un rapport, une interview sans contexte, une “alerte” santé sans référence : tout cela ressemble à du contenu généré pour capter des clics, pas pour informer.
Un exemple concret : HexaMedia avait publié une série d’articles “ce que l’on sait” sur une rumeur de produit high-tech. Les textes étaient prudents, mais citaient “des sources proches du dossier” sans aucune piste. En face, un concurrent renvoyait vers des dépôts de brevets, des déclarations publiques, et des documents d’autorités. À performance similaire en SEO, le concurrent prenait l’avantage sur Discover, car l’utilisateur obtient des repères.
Pourquoi la production de masse ressemble à du spam, même si elle est “originale”
La difficulté, c’est que le spam moderne peut être grammaticalement parfait. Les systèmes anti-abus de Google se concentrent donc sur des patterns : volumes anormaux, répétitions de structures, promesses non tenues, absence de responsabilité éditoriale. Un site peut publier 1 000 textes “uniques” et pourtant offrir une expérience pauvre, surtout si chaque article réécrit vaguement la même dépêche.
Le point d’équilibre se joue souvent sur l’intention : informer ou occuper l’espace ? À la fin, l’insight est simple : la visibilité sur Discover se mérite moins par la quantité que par la démonstration de fiabilité.
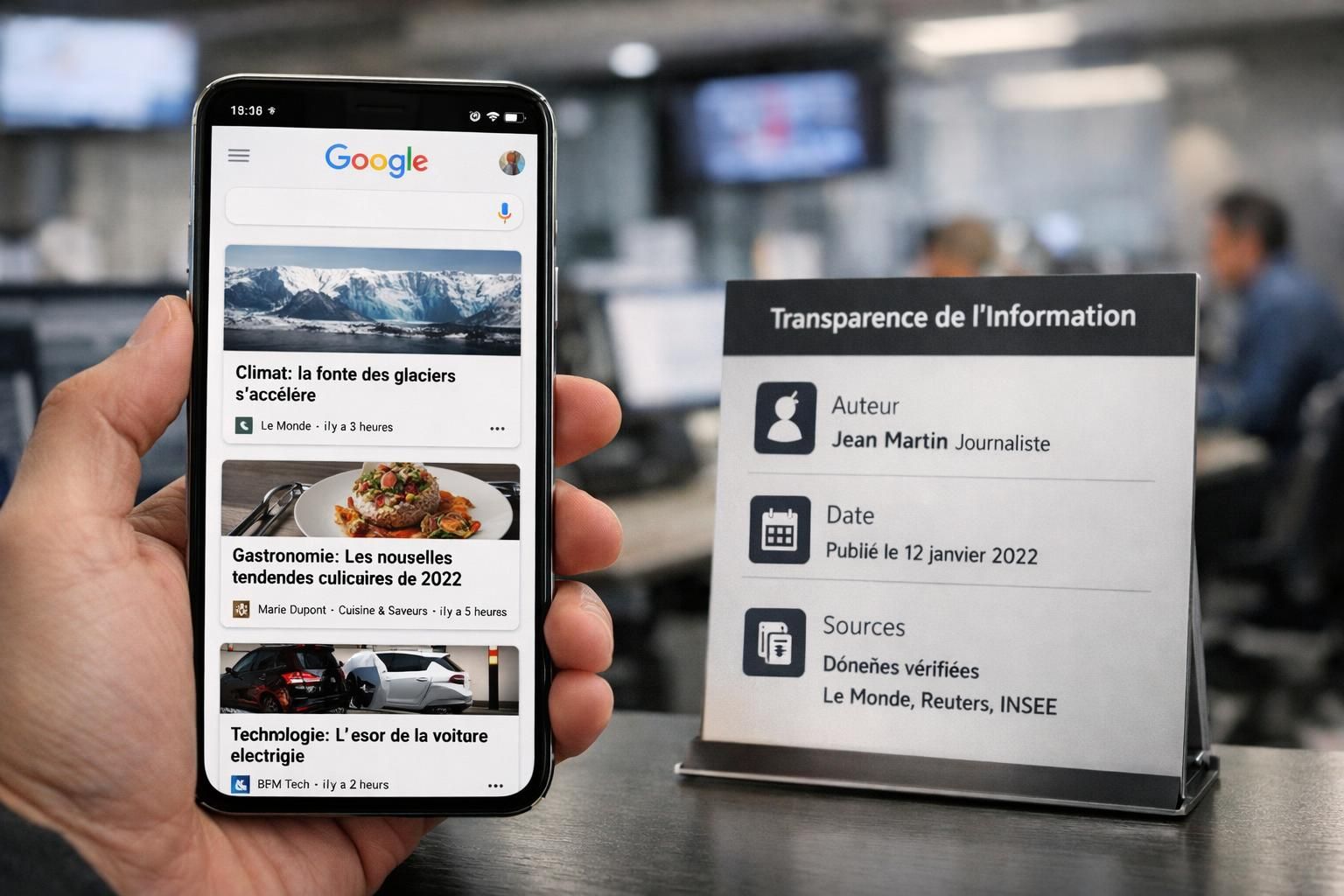
Pénalités manuelles sur Discover : transparence, fiabilité et responsabilité éditoriale
Un changement marquant est la montée en puissance des actions humaines, au-delà des filtres automatiques. Des éditeurs ont reçu des notifications via Search Console mentionnant des manquements à des règles de transparence : absence de date claire, auteur introuvable, informations de contact floues, ou identité éditoriale indéterminée. Pour HexaMedia, ce fut un électrochoc : aucun “gros” contenu n’était mensonger, mais certaines pages manquaient d’éléments basiques (bio d’auteur, mentions légales accessibles, page “à propos” pauvre).
Pourquoi ce durcissement ? Parce que Discover, devenu central pour l’accès à l’info sur mobile, ne peut pas se permettre de recommander des sites où l’on ne sait pas “qui parle”. Dans un contexte où des faux médias ont été identifiés, parfois alimentés par des textes automatisés et des signatures inventées, l’exigence d’identification prend une valeur quasi sanitaire.
Ce que Google attend concrètement : signaux visibles et cohérents
Les exigences sont plus simples qu’elles n’en ont l’air : rendre l’éditeur “auditable”. L’utilisateur doit pouvoir retrouver une rédaction, une ligne, et des responsables. Cela rejoint un principe de presse classique, transposé au web.
- Auteur identifiable : nom, biographie crédible, liens vers d’autres publications, domaine d’expertise.
- Date et contexte : publication et mise à jour clairement affichées, surtout pour les sujets évolutifs.
- Mentions légales et contact : adresse ou structure, moyen de joindre la rédaction, informations vérifiables.
- Traçabilité des sources : liens, documents, citations attribuées, méthodologie si nécessaire.
- Usage de l’IA expliqué : lorsqu’un texte est co-produit, l’indiquer pour renforcer la confiance.
Cette liste n’est pas un “bonus”. C’est un socle. HexaMedia a constaté que, dès que ces éléments étaient uniformisés sur l’ensemble du site, la volatilité Discover diminuait, même sans augmenter la cadence de publication.
Tableau de contrôle : risques typiques et actions correctives
Signal observé |
Risque sur Discover |
Correction recommandée |
|---|---|---|
Auteur absent ou pseudonyme opaque |
Suspicion de site “usine”, baisse de visibilité |
Créer des pages auteurs complètes, relier chaque article à une bio |
Articles sans sources ni liens |
Dégradation perçue de la qualité de l’information |
Ajouter références, documents, citations attribuées, liens primaires |
Mentions légales introuvables |
Non-conformité aux attentes de transparence |
Rendre l’accès permanent (footer), préciser l’éditeur et un contact |
Production très élevée et uniforme |
Assimilation à contenus synthétiques produits en masse |
Réduire la cadence, augmenter l’originalité reportage/terrain |
Titres trop optimisés et “clickbait” |
Limitation de la diffusion, engagement négatif |
Rédiger des titres factuels, alignés avec le contenu réel |
À ce stade, la logique est nette : Discover récompense la responsabilité éditoriale autant que la pertinence. La section suivante bascule côté utilisateurs : car la personnalisation, qui fait la force du produit, explique aussi pourquoi ces ajustements ont tant d’impact.
Pour comprendre l’environnement de diffusion (et ses enjeux de gouvernance), certains dossiers sur la régulation des plateformes aident à mettre en perspective les décisions de recommandation, comme cette analyse sur les enjeux de contrôle et d’entités américaines, utile pour comparer les logiques de “flux” et de responsabilité.
Comment fonctionne Discover côté utilisateur : personnalisation, données et arbitrages de visibilité
Discover apparaît souvent par un simple glissement vers la gauche sur Android, et sur iOS via l’application Google. Sa promesse tient en une anticipation : proposer des contenus avant même la recherche, en s’appuyant sur l’historique, l’activité web et applications, et les interactions avec les cartes (clics, masquages, abonnements à des thèmes). En surface, c’est confortable. En coulisses, c’est un système de profilage d’intérêts qui doit concilier pertinence et sécurité.
Cette mécanique explique le durcissement envers les contenus synthétiques non sourcés. Imaginez un utilisateur passionné d’économie, qui clique sur des analyses. Si Discover lui recommande ensuite une série d’articles “finance” produits en masse, imprécis, et sans références, l’utilisateur perd confiance dans le flux entier. La conséquence, pour Google, c’est une baisse d’engagement et une fragilisation du produit. D’où l’ajustement actuel : mieux vaut recommander moins, mais recommander mieux.
Personnaliser plutôt que couper : réglages qui influencent le flux
Le débat “faut-il désactiver Discover ?” revient régulièrement, pour des raisons de distraction, de consommation de données, ou d’intimité. Pourtant, la plupart des utilisateurs gagnent à le piloter. Un lecteur peut indiquer “pas intéressé”, masquer un média, ou au contraire renforcer un thème via les signaux positifs. Cette boucle de feedback modifie directement ce qui remonte, et donc ce qui est monétisable.
Pour un éditeur comme HexaMedia, cela change la stratégie : il ne suffit pas d’obtenir un clic. Il faut produire un article que l’utilisateur voudra voir à nouveau, sauvegarder, ou partager. Autrement dit, la valeur perçue redevient la meilleure optimisation.
Lecture automatique des vidéos, données mobiles et perception de qualité
Les vidéos qui se lancent toutes seules peuvent agacer et donner une impression “publicitaire”. Les réglages permettent de limiter la lecture automatique (jamais, Wi‑Fi seulement, ou Wi‑Fi + mobile). Ce détail compte : un flux jugé envahissant est moins consulté, et la chaîne de diffusion se referme pour tout le monde.
En toile de fond, la question de la confidentialité reste centrale : gestion de l’historique, de l’activité web, et personnalisation publicitaire. Pour les marques médias, l’enjeu est indirect mais réel : plus l’utilisateur se sent en contrôle, plus il accepte la recommandation. L’insight final est immédiat : le confort utilisateur devient un critère invisible de visibilité éditoriale.

Produire des contenus compatibles Discover en 2026 : sources, format humain et cohérence éditoriale
La tentation, face à la baisse de portée, est de “sur-optimiser” : titres calibrés, structures répétitives, multiplication de brèves. Or Discover semble justement se détourner de ces schémas trop mécaniques. Pour HexaMedia, la remontée s’est faite quand la rédaction a accepté une règle simple : chaque article doit pouvoir être défendu comme un travail journalistique, même court. Cela passe par des sources claires, une attribution propre, et une promesse tenue.
Concrètement, un article Discover performant en 2026 ressemble moins à une page SEO classique qu’à une carte magazine : angle net, informations utiles, contexte, et une écriture qui n’a pas l’air d’avoir été “pompée” d’un gabarit. Les contenus synthétiques peuvent exister, mais à condition d’être encadrés, relus, et explicités quand c’est pertinent. La transparence n’est plus un risque réputationnel : c’est un facteur de fiabilité.
Exemple de “refonte” d’un article faible en article solide
Avant : “Nouveau smartphone X : tout ce qu’on sait”. Texte générique, aucune référence, un empilement de conditionnels. Après : “Smartphone X : ce que confirment les documents, ce que disent les dirigeants, et ce que supposent les fuites”. Même sujet, mais trois niveaux d’information hiérarchisés. On cite un communiqué, on relie à une conférence, on encadre la rumeur. Résultat : l’utilisateur comprend ce qui est certain et ce qui ne l’est pas.
Cette démarche réduit la probabilité d’être classé dans la catégorie “contenu produit pour remplir”. Et elle facilite aussi le travail de relecture interne : un rédacteur en chef peut valider l’article plus vite, car la structure rend l’incertitude visible.
Checklist opérationnelle pour ne pas subir la limitation de diffusion
- Affichez l’auteur et ajoutez une bio crédible, même sur les brèves.
- Documentez les sources : lien primaire, document, citation, ou méthodologie.
- Évitez les titres trompeurs : Discover mesure fortement la satisfaction après clic.
- Stabilisez les gabarits sans les rendre identiques : variété de formats et d’angles.
- Indiquez les mises à jour quand l’information évolue, pour éviter l’obsolescence.
- Encadrez l’IA : relecture, ajout de contexte, et transparence quand nécessaire.
Le bénéfice est double : vous améliorez l’expérience lecteur, et vous envoyez à l’algorithme des signaux cohérents. La phrase-clé à retenir est pragmatique : sur Discover, la performance est la conséquence d’une crédibilité démontrable.
Pour approfondir la logique officielle côté Google, la documentation “Search Central” sur l’apparition dans Discover est une ressource utile : les recommandations Google pour apparaître sur Discover détaillent les attentes générales, même si la mise en œuvre dépend fortement des signaux de confiance.
Publicités, confidentialité et confiance : pourquoi Google relie monétisation et fiabilité des contenus
Dans Discover, la publicité n’est pas un simple “habillage”. Elle fait partie de l’expérience, et donc de la perception de sérieux. Un flux saturé d’annonces mal ciblées, ou associé à des articles douteux, déclenche une réaction de rejet. Pour Google, l’équation est donc commerciale et éditoriale : préserver l’attention, éviter la fatigue, et maintenir la confiance. C’est aussi pour cela que la limitation des contenus synthétiques non sourcés devient prioritaire : un environnement de recommandation n’est rentable que s’il est crédible.
HexaMedia l’a vécu de façon indirecte. Lorsqu’un ensemble de pages a été jugé “trop léger” (peu de contexte, signatures inconsistantes), non seulement la visibilité a chuté, mais le RPM publicitaire sur mobile s’est dégradé : moins de pages vues, plus de rebonds, moins de sessions récurrentes. Le problème n’était pas “la pub”, mais la confiance, qui conditionne la durée de lecture.
Contrôle des annonces et signaux de confort côté utilisateur
Les utilisateurs peuvent masquer un annonceur, réduire la personnalisation, ou ajuster les données utilisées pour le ciblage via les réglages du compte Google. Même si cela semble éloigné des éditeurs, l’effet est réel : un utilisateur qui maîtrise ce qu’il voit a tendance à conserver Discover dans ses habitudes. Cette fidélité alimente ensuite la distribution des articles, à condition qu’ils restent au niveau attendu.
On retrouve ici une logique comparable aux grandes plateformes sociales : la bataille se joue autant sur la gouvernance que sur le contenu. Les débats autour des entités, de la régulation et des responsabilités (souvent discutés à propos d’autres applications) rappellent que la recommandation algorithmique n’est jamais neutre. Elle est un produit, avec des arbitrages.
Fiabilité éditoriale : le point de jonction entre SEO, Discover et marque média
La conséquence la plus structurante pour 2026 est culturelle : les rédactions doivent rapprocher SEO, social et Discover autour d’un même standard de transparence. Un article peut être “bon” et pourtant échouer sur Discover s’il ne dit pas clairement qui écrit, à quelle date, et sur quelle base factuelle. Inversement, un article modeste peut très bien fonctionner s’il est utile, clair, et correctement attribué.
Ce n’est pas un retour en arrière vers un web “institutionnel”. C’est une sélection par la confiance, rendue nécessaire par l’abondance. L’insight final de cette section tient en une formule : plus la production est facile, plus la preuve de fiabilité devient la vraie valeur.